How does AIC work?
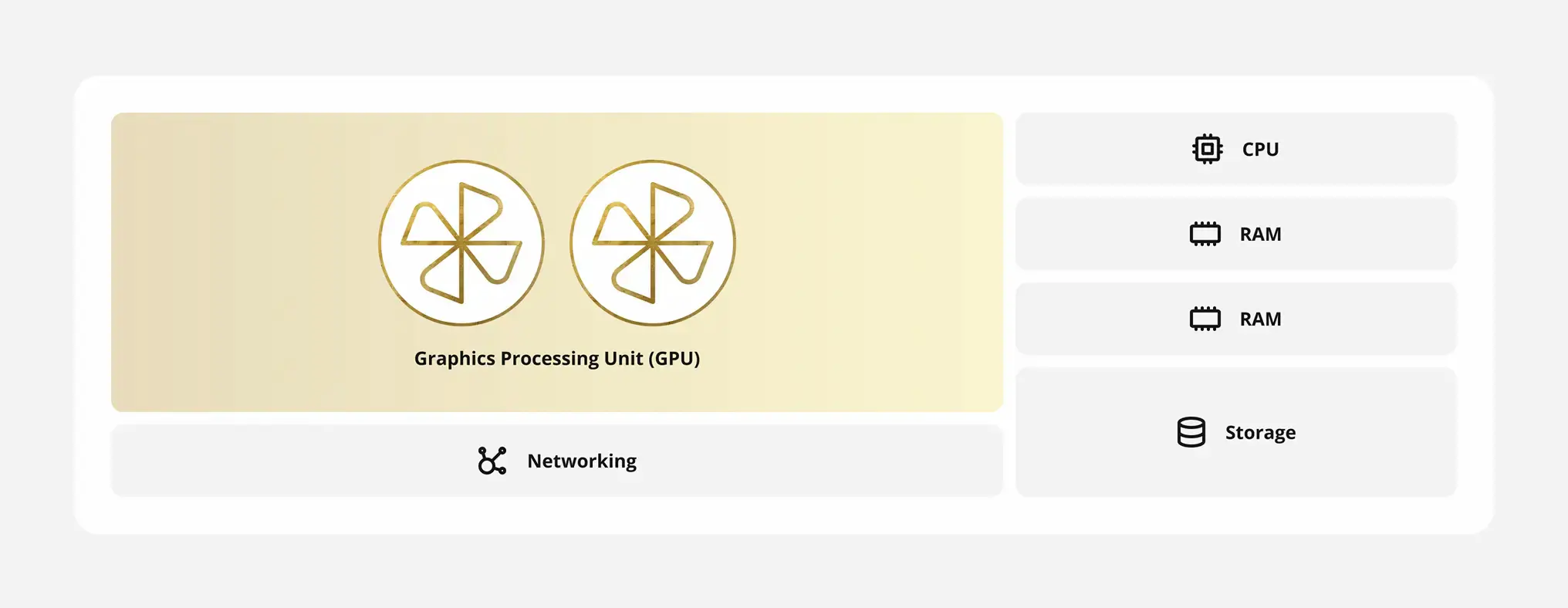
Our AIC service is built on the same dedicated bare metal hardware that we use as part of our Enterprise Bare Metal (EBM) service. Just like EBM, businesses using AIC rent out and maintain sole tenancy over entire physical servers that can be customized based on specific business and performance criteria.
But while EBM brings the powerful baseline CPU-led compute, AIC introduces GPU configurations to run compute-heavy AI workloads.
AIC architectures are also tailored to specific machine learning use cases, training pipelines and model sizes with optimized CPU, memory and storage configurations. These configurations support all major machine learning frameworks including PyTorch, TensorFlow and ONYX. Most significantly, our AIC service allows for the selection and use of any available GPU unit on the global market.
This makes AIC ideal for a variety of use cases. For example, AIC is perfectly suited to high-throughput training that relies on parallel processing and large datasets, as well as distributed training workloads like large language model (LLM) training.
Beyond training models, AIC also supports vector databases like Weaviate and Qdrant that are essential for building and deploying AI-powered applications.
For most organizations, it’s necessary to run a combination of CPU and GPU processors – not just one or the other. For example, you may need CPUs for general purpose applications and the parallel processing capabilities of GPUs to support concurrent high-performance computing.
If you’re managing these workflows across separate network architectures, this can create additional operational complexity.
This is where utilizing AIC as part of our hybrid bare metal cloud solution is beneficial. By adopting a hybrid bare metal cloud approach, you can mix predictable CPU workloads hosted on EBM, “burst” workloads on Scalable Bare Metal (SBM), and GPU-heavy workloads on AIC, all via a single private network.
Hosting everything on one private network also offers several benefits like enhanced security, more control over your infrastructure, and cost efficiency from reduced latency and data bandwidth costs.